What Is a Saga Pattern?
A saga is a sequence of local transactions that update multiple services without a global ACID transaction. Each local step commits in its own database and publishes an event or sends a command to trigger the next step. If any step fails, the saga runs compensating actions to undo the work already completed. The result is eventual consistency across services.
How Does It Work?
Two Coordination Styles
- Choreography (event-driven): Each service listens for events and emits new events after its local transaction. There is no central coordinator.
Pros: simple, highly decoupled. Cons: flow becomes hard to visualize/govern as steps grow. - Orchestration (command-driven): A dedicated orchestrator (or “process manager”) tells services what to do next and tracks state.
Pros: clear control and visibility. Cons: one more component to run and scale.
Compensating Transactions
Instead of rolling back with a global lock, sagas use compensation—business-level “undo” (e.g., “release inventory”, “refund payment”). Compensations must be idempotent and safe to retry.
Success & Failure Paths
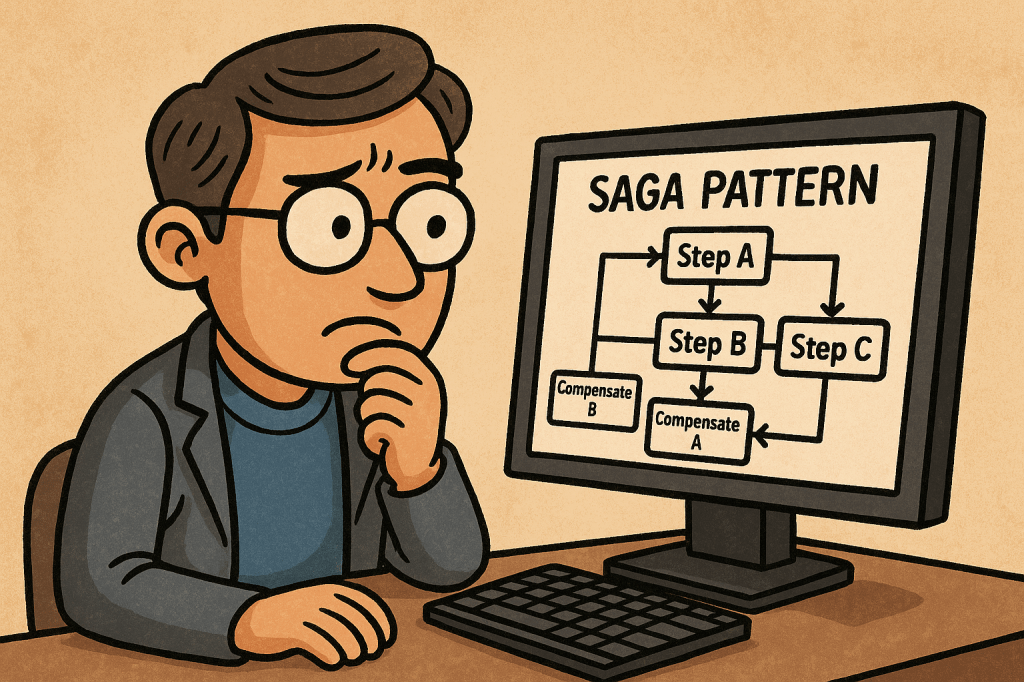
- Happy path: Step A → Step B → Step C → Done
- Failure path: Step B fails → run B’s compensation (if needed) → run A’s compensation → saga ends in a terminal “compensated” state.
How to Implement a Saga (Step-by-Step)
- Model the business workflow
- Write the steps, inputs/outputs, and compensation rules for each step.
- Define when the saga starts, ends, and the terminal states.
- Choose coordination style
- Start with orchestration for clarity on complex flows; use choreography for small, stable workflows.
- Define messages
- Commands (do X) and events (X happened). Include correlation IDs and idempotency keys.
- Persist saga state
- Keep a saga log/state (e.g., “PENDING → RESERVED → CHARGED → SHIPPED”). Store step results and compensation status.
- Guarantee message delivery
- Use a broker (e.g., Kafka/RabbitMQ/Azure Service Bus). Implement at-least-once delivery + idempotent handlers.
- Consider the Outbox pattern so DB changes and messages are published atomically.
- Retries, timeouts, and backoff
- Add exponential backoff and timeouts per step. Use dead-letter queues for poison messages.
- Design compensations
- Make them idempotent, auditable, and business-correct (refund, release, cancel, notify).
- Observability
- Emit traces (OpenTelemetry), metrics (success rate, average duration, compensation rate), and structured logs with correlation IDs.
- Testing
- Unit test each step and its compensation.
- Contract test message schemas.
- End-to-end tests for happy & failure paths (including chaos/timeout scenarios).
- Production hardening checklist
- Schema versioning, consumer backward compatibility
- Replay safety (idempotency)
- Operational runbooks for stuck/partial sagas
- Access control on orchestration commands
Mini Orchestration Sketch (Pseudocode)
startSaga(orderId):
save(state=PENDING)
send ReserveInventory(orderId)
on InventoryReserved(orderId):
save(state=RESERVED)
send ChargePayment(orderId)
on PaymentCharged(orderId):
save(state=CHARGED)
send CreateShipment(orderId)
on ShipmentCreated(orderId):
save(state=COMPLETED)
on StepFailed(orderId, step):
runCompensationsUpTo(step)
save(state=COMPENSATED)
Main Features
- Long-lived, distributed workflows with eventual consistency
- Compensating transactions instead of global rollbacks
- Asynchronous messaging and decoupled services
- Saga state/log for reliability, retries, and audits
- Observability hooks (tracing, metrics, logs)
- Idempotent handlers and deduplication for safe replays
Advantages & Benefits (In Detail)
- High availability: No cross-service locks or 2PC; services stay responsive.
- Business-level correctness: Compensations reflect real business semantics (refunds, releases).
- Scalability & autonomy: Each service owns its data; sagas coordinate outcomes, not tables.
- Resilience to partial failures: Built-in retries, timeouts, and compensations.
- Clear audit trail: Saga state/log makes post-mortems and compliance easier.
- Evolvability: Add steps or change flows with isolated deployments and versioned events.
When and Why You Should Use It
Use sagas when:
- A process spans multiple services/datastores and global transactions aren’t available (or are too costly).
- Steps are long-running (minutes/hours) and eventual consistency is acceptable.
- You need business-meaningful undo (refund, release, cancel).
Prefer simpler patterns when:
- All updates are inside one service/database with ACID support.
- The process is tiny and won’t change—choreography might still be fine, but a direct call chain could be simpler.
Real-World Examples (Detailed)
- E-commerce Checkout
- Steps: Reserve inventory → Charge payment → Create shipment → Confirm order
- Failure: If shipment creation fails, refund payment, release inventory, cancel order, notify customer.
- Travel Booking
- Steps: Hold flight → Hold hotel → Hold car → Confirm all and issue tickets
- Failure: If hotel hold fails, release flight/car holds and void payments.
- Banking Transfers
- Steps: Debit source → Credit destination → Notify
- Failure: If credit fails, reverse debit and flag account for review.
- KYC-Gated Subscription
- Steps: Create account → Run KYC → Activate subscription → Send welcome
- Failure: If KYC fails, deactivate, refund, delete PII per policy.
Integrating Sagas into Your Software Development Process
- Architecture & Design
- Start with domain event storming or BPMN to map steps and compensations.
- Choose orchestration for complex flows; choreography for simple, stable ones.
- Define message schemas (JSON/Avro), correlation IDs, and error contracts.
- Team Practices
- Consumer-driven contracts for messages; enforce schema compatibility in CI.
- Readiness checklists before adding a new step: idempotency, compensation, timeout, metrics.
- Playbooks for manual compensation, replay, and DLQ handling.
- Platform & Tooling
- Message broker, saga state store, and a dashboard for monitoring runs.
- Consider helpers/frameworks (e.g., workflow engines or lightweight state machines) if they fit your stack.
- CI/CD & Operations
- Use feature flags to roll out steps incrementally.
- Add synthetic transactions in staging to exercise both happy and compensating paths.
- Capture traces/metrics and set alerts on compensation spikes, timeouts, and DLQ growth.
- Security & Compliance
- Propagate auth context safely; authorize orchestrator commands.
- Keep audit logs of compensations; plan for PII deletion and data retention.
Quick Implementation Checklist
- Business steps + compensations defined
- Orchestration vs. choreography decision made
- Message schemas with correlation/idempotency keys
- Saga state persistence + outbox pattern
- Retries, timeouts, DLQ, backoff
- Idempotent handlers and duplicate detection
- Tracing, metrics, structured logs
- Contract tests + end-to-end failure tests
- Ops playbooks and dashboards
Sagas coordinate multi-service workflows through local commits + compensations, delivering eventual consistency without 2PC. Start with a clear model, choose orchestration for complex flows, make every step idempotent & observable, and operationalize with retries, timeouts, outbox, DLQ, and dashboards.


Recent Comments