When building efficient software, choosing the right data structure is critical. One of the most widely used and powerful data structures is the hash table. In this post, we’ll explore what a hash table is, why it’s useful, when to use it, and how it compares with a lookup table. We’ll also examine real-world examples and analyze its time and memory complexities.
What is a Hash Table?
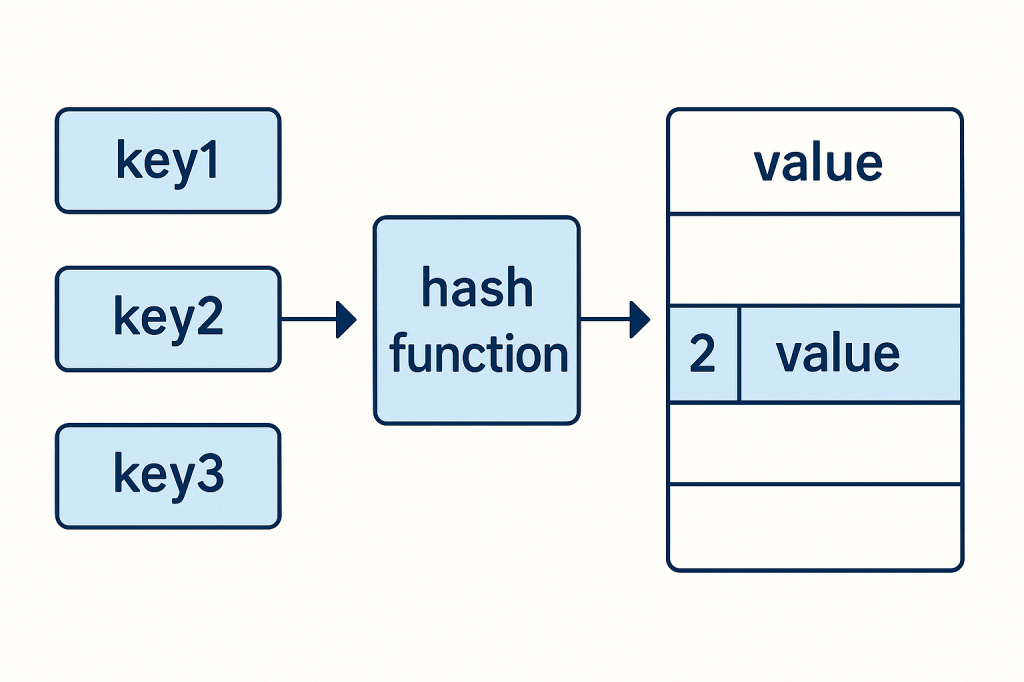
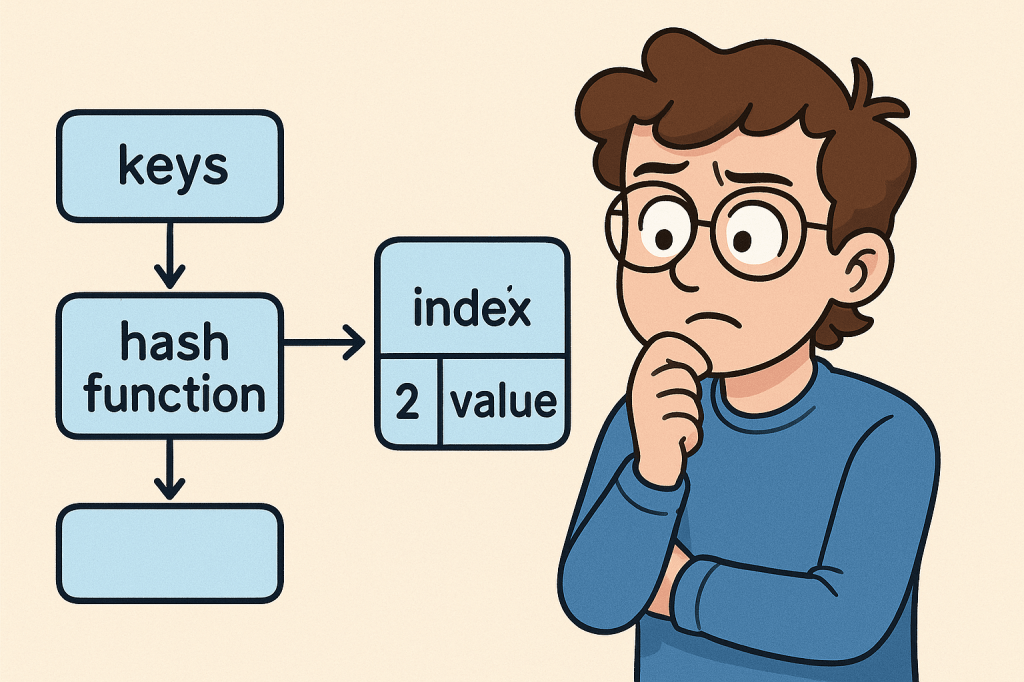
A hash table (also known as a hash map) is a data structure that stores key–value pairs.
It uses a hash function to convert keys into indexes, which point to where the corresponding value is stored in memory.
Think of it as a dictionary: you provide a word (the key), and the dictionary instantly gives you the definition (the value).
Why Do We Need a Hash Table?
Hash tables allow for fast lookups, insertions, and deletions. Unlike arrays or linked lists, where finding an item may take linear time, hash tables can usually perform these operations in constant time (O(1)).
This makes them essential for situations where quick access to data is needed.
When Should We Use a Hash Table?
You should consider using a hash table when:
- You need fast lookups based on a unique key.
- You are working with large datasets where performance matters.
- You need to implement caches, dictionaries, or sets.
- You want to avoid searching through long lists or arrays to find values.
Real-World Example
Imagine you are building a login system for a website.
- You store usernames as keys.
- You store hashed passwords as values.
When a user logs in, the system uses the username to quickly find the corresponding hashed password in the hash table and verify it.
Without a hash table, the system might need to search through a long list of users one by one, which would be very inefficient.
Time and Memory Complexities
Here’s a breakdown of the common operations in a hash table:
- Inserting an element → Average: O(1), Worst-case: O(n) (when many collisions occur)
- Deleting an element → Average: O(1), Worst-case: O(n)
- Searching/Lookup → Average: O(1), Worst-case: O(n)
- Memory Complexity → O(n), with additional overhead for handling collisions (like chaining or open addressing).
The efficiency depends on the quality of the hash function and how collisions are handled.
Is a Hash Table Different from a Lookup Table?
Yes, but they are related:
- A lookup table is a precomputed array or mapping of inputs to outputs. It doesn’t necessarily require hashing — you might simply use an array index.
- A hash table, on the other hand, uses hashing to calculate where a key should be stored, allowing flexibility for keys beyond just integers or array indexes.
In short:
- Lookup Table = direct index mapping (fast but limited).
- Hash Table = flexible key–value mapping using hashing.
Final Thoughts
Hash tables are one of the most versatile and powerful data structures in computer science. They allow developers to build high-performance applications, from caching systems to databases and authentication services.
Understanding when and how to use them can significantly improve the efficiency of your software.

Recent Comments